
Flat File :
Flat file refers to a specific file format used for data integration and processing. A flat file is a text file that contains data organized in a tabular or hierarchical structure, where each line represents a record and each field within a record is separated by a delimiter character, such as a comma, pipe, or tab.
In webMethods, you can work with flat files using the webMethods Flat File Schema, which is a metadata definition that describes the structure and format of the flat file. The Flat File Schema allows you to define record and field structures, specify delimiters, set field types, and define validation rules. With the help of Flat File Schemas, you can parse incoming flat files, transform them into a structured format, and perform various operations on the data within the webMethods Integration Server.
In webMethods, there are various flat file types that can be handled using the built-in features and components. The specific flat file types supported may depend on the version of webMethods you are using, but here are some common flat file types:
- Delimited Flat File: This is the most common type of flat file where fields within a record are separated by a delimiter character, such as a comma (CSV), pipe (|), tab, or any other specified character. Delimited flat files are widely used for data exchange and integration.

- Fixed Length Flat File: In this type of flat file, each field within a record has a fixed length, and there are no delimiters between the fields. The field lengths are predefined, and data is aligned based on those lengths. Fixed length flat files are often used in legacy systems and for data that requires strict positional formatting.



- Fixed length :
fixed length extractor is a type of field extractor used to parse flat files with a fixed-length format. It is specifically designed to handle flat files where each field within a record has a predefined length and there are no delimiters between the fields. - Nth Field :
The Nth field extractor is a commonly used type of extractor in flat files. It allows the extraction of fields based on their position within the file, starting from 0. This extractor type is widely preferred because it does not impose any limitations on the size of the field, unlike the Fixed Length extractor.
Components of flat file in WebMethods :
Handling flat files in webMethods involves several key components that aid in the processing, transformation, and integration of flat file data.
- Flat File Schema: The Flat File Schema in webMethods is a metadata definition that outlines the structure and format of a flat file. It specifies the record and field structures, determines the delimiters or fixed lengths used, defines field types, and establishes validation rules. Serving as a blueprint, the Flat File Schema enables the parsing, validation, and generation of flat files within the webMethods platform.Flat file schema has two sections where you need to configure the conditions to parse the Flat file.
- Flat File Definition : Flat File Definition is a set of rules and specifications that define the structure, layout, and data elements of a flat file, enabling accurate parsing and handling of flat file data during integration processes.
- Record Parser Type: It is an attribute that determines how individual records in the flat file should be parsed and processed during integration.

Now Let’s understand how the records needs to be parsed for each Record parser type.
- Delimiter :
- Record: “Record” defines the method of separating individual data records within the flat file, using specific delimiters to distinguish one record from another for proper parsing and integration.
- Field or Composite: Here we need to specify the method by which each field is separated within the flat file. This ensures that the data elements are appropriately delineated, allowing for accurate parsing and processing during integration.
- Subfield: refers to a smaller component or part of a larger field, typically used to represent hierarchical or structured data within a flat file.
- Quoted Release Character: It is a setting that allows for the inclusion of special characters, like delimiters, within a quoted string in a flat file while preventing them from being treated as actual delimiters during parsing and processing.
- Release Character: It is a designated character used to escape or interpret special characters within a flat file, ensuring they are handled correctly during parsing and processing.
- Fixed Length :
- Record Length: It is an attribute that determines how individual records in the flat file should be parsed and processed during integration.
- Please refer to other fields from the above delimiter configuration as it serves the same purpose.
- Delimiter :
- Record Parser Type: It is an attribute that determines how individual records in the flat file should be parsed and processed during integration.
- Flat File Structure: Flat File Structure refers to the organized arrangement of data elements within a flat file, including segments, records, and fields, which are defined by the flat file dictionary to ensure proper interpretation and processing during integration operations. When creating the structure of the data within this schema, it becomes specific to this particular integration and cannot be reused in other scenarios. However, by utilizing an externally created flat file dictionary, the schema can reference it, allowing for broader applicability across various integration scenarios, ensuring consistency, and facilitating easy reusability in multiple contexts.
- Flat File Definition : Flat File Definition is a set of rules and specifications that define the structure, layout, and data elements of a flat file, enabling accurate parsing and handling of flat file data during integration processes.
- Flat File Dictionary: Within webMethods, the Flat File Dictionary serves as a centralized repository for a collection of pre-defined Flat File structure that can be utilized across multiple projects. By storing and managing commonly used structures in a single location, it promotes consistency and reusability in the handling of flat files.Let’s first understand the below terms in flat file Dictionary.
- Record Definition : Record definition refers to the specification of a unit of data within a flat file. Records are composed of multiple segments, and they represent a logical grouping of related data elements. Each record definition in the FlatFile Dictionary describes the sequence and structure of segments within that record.
- Composite Definition : Composite Definition refers to a special type of field definition used to group multiple segments together under a single name. It allows for the creation of structured elements within a flat file, making it easier to organize and interpret complex data.
- Field Definition : Field Definition refers to the specification of an individual data element within a flat file. It defines the characteristics and attributes of the data, such as data type, length, and occurrence.

- Create a flat file dictionary with name delimittedDictonary.

- Let’s first understand the below terms in flat file Dictionary.
- Create a new record named “EmployeeDetails” by right-clicking on the record definition.

- Now we need to define the field details in the “EmployeeDetails” record which we can create by right clicking on it but let let’s first define the field in “Field Definition” and then we will reference them inside “EmployeeDetails” record, this process will help us to reuse the filed.
- To create a new field, right-click on the “Field Definition” section and select “New.” Give the field a name, and then proceed to create the following fields within the “Field Definition” section.

- To reference the fields within the “EmployeeDetails” record, follow these steps: Right-click on the “EmployeeDetails” record definition, choose “New,” and then select “Field Reference.” Click “Next,” and select the appropriate dictionary. Proceed to select the fields we previously created in the “Field Definition” section, starting with “Name,” and click “Next.” Set the “Extractor Type” to “Nth Field,” and if you want a field to be mandatory, check the “Mandatory” option for validation. Ensure to set the position to ‘0’ for the first field and increment it accordingly for the subsequent fields. Repeat this procedure for each field you want to include in the “EmployeeDetails” record.



- Now the final structure will look like below.

- Next, we will configure the schema to parse the flat file.
- Let’s create a “Flat file Schema” named “delimitedSchema” and proceed to open it for configuration.

- Follow the below steps to configure below fields to parse the flat file schema.
- Select the “delimiter” option as the “Record Parser Type” since our flat file’s fields are separated by the ‘,’ delimiter.
- Now, configure the “Character” setting for “Record” to be a new line. This defines how each record is separated, and in our case, it is by a new line.
- Configure the “Character” setting for “Field or Composite” to ‘,’ as our flat file has its fields separated by this delimiter.
- We don’t need to configure other fields as it is not application for our Flat File.

- Now, we need to reference the document structure that we created earlier.
- In the Schema properties section, set the “Default Record” option to the dictionary created in the earlier step.

- Next, to generate the document from the created structure, navigate to the “Flat File Structure” of the schema. In the upper corner, locate and click on the document icon to create the desired document.


- Upon opening the generated document, you’ll observe that it contains a list of documents named “recordWithNoID” instead of the record name defined in the dictionary. However, there’s a concept behind this behavior, which we will cover in detail in the upcoming article. Stay tuned for more insights!

- Create a new record named “EmployeeDetails” by right-clicking on the record definition.
- Create a flat file dictionary with name delimittedDictonary.













- We have all the setup in place so it’s time to create a flow service that will efficiently parse the flat file using the schema we have meticulously created.
- Create a flow service with name “delimittedFileParser”.
- Invoke “convertToValues” from “WmFlatFile” package which will parse the flat file to the document.

- Now if you will observe in the screenshot you will notice that it is looking for “ffData” which is of type object so we need to convert our flat file content to an object.
- Add one map step before the “convertToValues” step and in the pipeline out and create a string variable with name “flatfile” and hard code the flat file content which was mentioned in the starting section of this article.

- After the map step, invoke the “pub.string:stringToBytes” service and follow below mapping, which will convert the flat file data from its current format to the object format.

- Now in the “pub.flatFile:convertToValues” step, you should map the “bytes” variable to the “ffData” input. Additionally, for the “ffSchema” variable, you should hardcode the full path of the schema that was previously created and map the “ffValues” document to a newly created document referencing it from the document created from the schema . As there is no validation required for other fields related to this flat file, they can remain unchanged. This configuration ensures that the “convertToValues” step will utilize the provided schema path for processing the flat file data.

- Now we have completed all the necessary steps for parsing the delimited flat file now completed, it’s time to execute the pipeline and observe the outcome.

- Boom we have our result as expected😀.





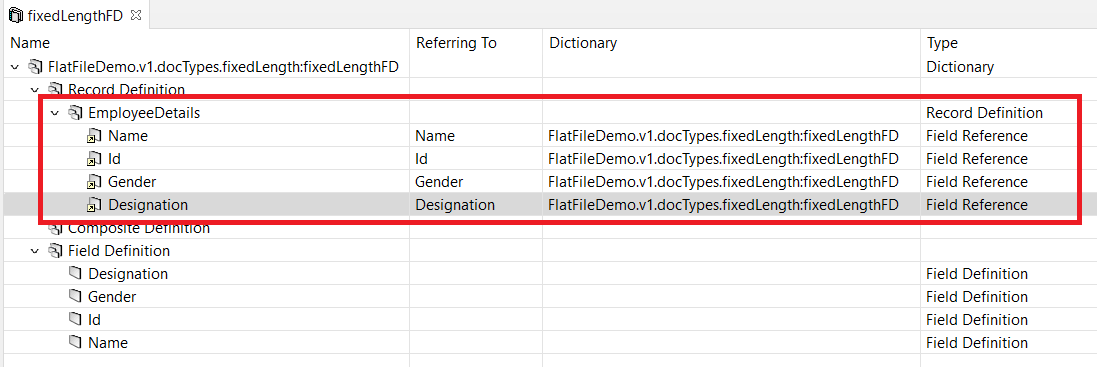
- Create a flat file dictionary with name “fixedLengthFD”.
- Create four fields with name “Name”,”Id”,”Gender”,”Designation” in the the field definition section like below.

- Now create a record with name “EmployeeDetails” in the “Record Definition” where we will define the field reference and the structure.

- Now perform the below steps to add field reference into the record created.
- Right-click on the “EmployeeDetails” record.
- From the context menu, choose “New.”
- Then, select “Field Reference.”
- A dialog box will appear, prompting you to choose the dictionary where the fields are defined. In this case, select the “fixedLengthFD” dictionary.
- Within the “fixedLengthFD” dictionary, locate and select the “Name” field and click Next.

- Upon selecting the “Extractor Type” as “Fixed Length,” which aligns with our objective of parsing the fixed length flat file, you will be prompted to specify the starting index and ending index for the “Name” field. Please provide the appropriate values for these indices to accurately define the fixed length of the “Name” field within the flat file.
- Now Let’s Check Our flat file where it is starting and where it is ending.

- As seen in the above screenshot, the starting and ending positions for each fields are provided by counting the number of characters within the fixed length flat file. In order to define the correct positions accurately, follow the same approach of counting characters within the file.
- Now for the “Name” filed put the start index as ‘0’ and end index as ’13’ so the field length will be ’14’, and same way add other fields and provide below starting and ending position.

- Now we have completed our configuration for the flat file dictionary so save it.






- Create a flat file schema with the name “fixedLengthSC” and refer the above dictionary to the “Default Record” like we did it in the previous exercise for delimited flat file.

- Now set the “Record parser type” to “Fixed length.” Since each record in the flat file consists of 54 characters, specify the “Record length” as ’53’ as it is starting from ‘0’ to ensure the parser correctly identifies and processes each record based on this fixed length.

- Now generate the the document structure the way we created earlier in the delimited flat file exercise, this will help us if we need to do any data mapping going forward.


- Create a flow service with name “fixedLengthFileParser” where we will invoke services for our record parser.
- Add one map step and create one variable with name “flatFile” where we will hardcode the flat file content.(You can create a variable in the service input to take the flat file content but for this exercise I am hardcoding it as I need to share the source code with you all).

- Invoke “pub.string:stringToBytes” and map and follow the below mapping which will help us to convert our sting to bytes and the same we can use further for parsing.

- Invoke “pub.flatFile:convertToValues” and in “ffSchema” hardcode your schema full path and follow below mappings.

- It’s time to run our service and see the outcome.

- Congratulations!! we got the result as expected.Note : You can skip the string to bytes conversion in both the exercises and directly map the the ‘flatfile’ string variable to the ‘ffData’ variable, it will work as well but for the demo purpose I have added the conversion step.








Hope you have enjoyed this article, click below download button to download the source code😊.
